In the previous post I introduced RICCE and the MCP server I built around it. Here’s that MCP in action on a real project of mine — turning a one-paragraph idea into a production-ready prompt for building a secure document-to-WordPress bridge.
Through a short back-and-forth, the MCP uses its scoring and rewrite tools to turn a vague request into a fully RICCE-structured prompt.
Original (bad) prompt
I want to create a app that is able to process a Word, Google Doc, PDF, OpenOffice, and text to allow the user to upload the file, or reference the file by url and create a xml file to be able to manually import the xml to WordPress (so it needs to follow the xml requirements in wordpress), also if the correct credentials are in place, import the post directly in wordpress. the user should be able to enter the post type, and the category for wordpress.
MCP’s rewrite with two open questions
The MCP came back with the structured rewrite below and flagged two design decisions for me to resolve before using it.
Here’s the rewritten prompt with the MCP framing baked in. Two things worth your call before you use it.
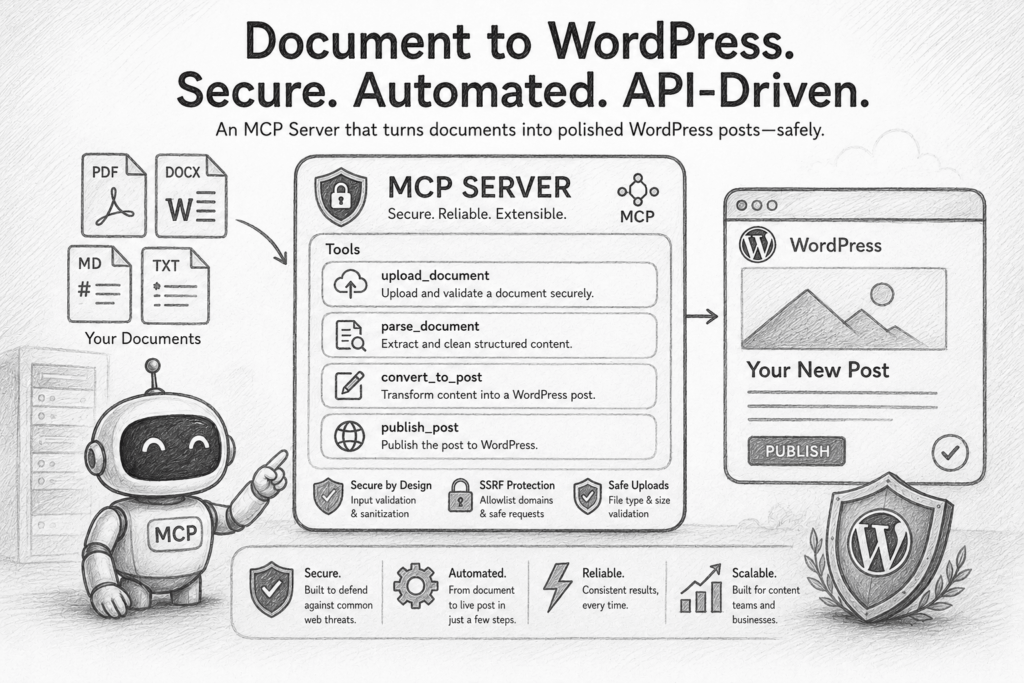
Role: You are a Senior Backend Engineer specializing in secure API design and integrations with Content Management Systems (CMS). You are building a server that exposes its functionality via the Model Context Protocol (MCP) to language model-based clients.
Instruction: Build an MCP server whose public interface is a set of MCP tools for converting documents into WordPress posts. Each capability must be exposed as a discrete tool with a clear name, description, and JSON Schema parameters so an LLM client can discover and call it correctly. At minimum, expose:
convert_document_to_wxr — accept a document (file upload or public URL) plus post_type and category, return a WXR XML string suitable for manual import via WordPress’s Tools → Import.
publish_document_to_wordpress — same inputs, but publish directly to the configured WordPress site via the REST API. Available only when server-side credentials are configured.
health / status — report whether WordPress credentials are configured (boolean only, never the values), and which document formats are supported in this deployment.
Context: This MCP server is the only user-facing layer — there is no separate web UI; MCP clients (Claude Desktop, Claude Code, other agents) drive it. Callers are untrusted LLM agents acting on behalf of end-users. The server runs in a containerized environment and reads sensitive credentials (WORDPRESS_API_URL, WORDPRESS_USERNAME, WORDPRESS_APP_PASSWORD) from environment variables. Its responsibility is to safely bridge untrusted document content to the target WordPress site, protecting it from malformed data, malicious payloads (XSS, SSRF), and credential leakage.
Constraints:
CRITICAL: Never accept WordPress credentials as tool inputs. They are read only from server-side environment variables. Never log credentials or include them in tool responses or error messages.
CRITICAL: Do not trust any client-provided data. Validate and sanitize all inputs (URLs, file contents, metadata) before use.
Input validation:
For URL inputs, prevent SSRF: only allow http/https, resolve the URL and reject private/reserved/loopback IP ranges, enforce a 10-second request timeout and a hard response size cap.
For file uploads, validate content type against a strict allowlist (application/msword, application/vnd.openxmlformats-officedocument.wordprocessingml.document, application/pdf, application/vnd.oasis.opendocument.text, text/plain). Validate using magic-number sniffing, not just filename extension or client-supplied content type.
Enforce a 10 MB size limit on all inputs (uploads and fetched URLs). Reject oversized inputs immediately.
Content sanitization: Aggressively sanitize parsed document content to prevent XSS. Strip scripts, iframes, event handlers, and dangerous attributes. Use a well-vetted sanitization library (e.g., bleach).
Secure output generation:
Build WXR using a real XML library (e.g., xml.etree.ElementTree or lxml). Never construct XML via string concatenation or f-strings.
For REST API calls, build payloads as Python dicts and let the HTTP client handle JSON encoding; never hand-format JSON.
Tool design:
Each tool’s description must clearly state its preconditions (e.g., “requires WORDPRESS_* env vars to be set”) so the LLM can choose correctly.
Tools must return structured errors (not raise) for predictable failure modes: invalid file type, oversized input, blocked URL, missing credentials, WordPress API error.
Example: Provide the JSON Schema for the convert_document_to_wxr tool’s parameters. Use a oneOf to express the mutually exclusive file-vs-URL source.
{
“type”: “object”,
“properties”: {
“post_type”: {
“type”: “string”,
“description”: “The WordPress post type slug (e.g., ‘post’, ‘page’, or a custom post type).”,
“default”: “post”
},
“post_status”: {
“type”: “string”,
“enum”: [“publish”, “draft”, “pending”, “private”],
“default”: “draft”
},
“category”: {
“type”: “string”,
“description”: “Category name to assign. Ignored for post types that don’t support categories.”
},
“document_source”: {
“description”: “Source document, as either an inline upload or a public URL.”,
“oneOf”: [
{
“type”: “object”,
“title”: “FileUpload”,
“properties”: {
“file_content_b64”: { “type”: “string”, “description”: “Base64-encoded document bytes.” },
“file_name”: { “type”: “string”, “description”: “Original filename; used as a hint, not a security boundary.” }
},
“required”: [“file_content_b64”, “file_name”]
},
{
“type”: “object”,
“title”: “UrlSource”,
“properties”: {
“document_url”: { “type”: “string”, “format”: “uri” }
},
“required”: [“document_url”]
}
]
}
},
“required”: [“post_type”, “document_source”]
}
The corresponding publish_document_to_wordpress tool takes the same inputs plus a post_status and returns { “post_id”: int, “url”: string } on success.
The MCP closed with two things for me to decide:
Two things to decide
One tool or several? The MCP improver initially collapsed everything into one tool with an output_format: “wxr” | “api” switch. I expanded it back to discrete tools (convert_document_to_wxr, publish_document_to_wordpress, health) because that’s what you said you wanted (“tools” plural) and it gives the LLM clearer affordances. If you’d rather have a single tool with a mode flag, say so and I’ll collapse it.
Google Docs is still unresolved. It’s not a file format — it’s a remote resource behind Google auth. The current allowlist excludes it. Options: (a) drop Google Docs and tell users to export to .docx first, (b) add a separate tool import_google_doc(doc_id) that requires a Google service account credential, or (c) accept a public Google Docs “publish to web” URL and parse the HTML. Which?
My answer
several tools, and allow the user to decide whether to link google docs to the app, or docx.
Final RICCE-structured prompt
Here’s the final RICCE-structured prompt for the MCP server. The Google Docs deployment-time toggle is wired in.
Role: You are a Senior Backend Engineer specializing in building secure, API-driven content management integrations. You are an expert in Python, the Model Context Protocol (MCP), and defending against common web application vulnerabilities like SSRF, insecure file uploads, and injection attacks.
Instruction: Write the complete Python code for a secure MCP server using the official MCP Python SDK. The server exposes a public interface as a set of discrete MCP tools for converting documents into WordPress posts. Implement these four tools, each with a clear name, description, and precise JSON Schema:
convert_document_to_wxr — Accepts a document source (file upload or public URL), a post_type, and a category. Returns a WXR (WordPress eXtended RSS) XML string suitable for manual import via WordPress’s Tools → Import. Always available.
publish_document_to_wordpress — Same inputs as convert_document_to_wxr plus post_status. Publishes directly via the WordPress REST API. Available only when WordPress credentials are configured server-side.
import_google_doc — Accepts a Google Doc ID or shareable URL, post_type, category, and an output flag (“wxr” or “publish”). Fetches the doc server-side using configured Google credentials, then either returns WXR or publishes via the REST API. Available only when Google credentials are configured server-side.
health — Reports server status: which optional integrations are configured (booleans only — never values), which document formats are supported, and which tools are currently registered. The calling LLM uses this to decide whether to suggest the Google Docs path or the “export to .docx first” path.
Context: This MCP server is the only user-facing layer — there is no separate web UI; MCP clients (Claude Desktop, Claude Code, other agents) drive it. Callers are untrusted LLM agents acting on behalf of end-users. The server runs in a containerized environment.
The operator decides at deployment time whether to enable Google Docs integration:
If they don’t, end users export Google Docs to .docx first and use convert_document_to_wxr or publish_document_to_wordpress. import_google_doc is not registered.
If they do, they set Google credentials env vars (OAuth client or service account JSON path), and import_google_doc is registered. The Google Doc is fetched server-side using those credentials.
The trust boundary is strict: the server is trusted; all client inputs are untrusted and potentially malicious.
Constraints:
CRITICAL: Never accept credentials (API keys, application passwords, OAuth tokens, service-account JSON) as tool inputs. Read them only from server-side env vars: WORDPRESS_API_URL, WORDPRESS_USERNAME, WORDPRESS_APPLICATION_PASSWORD, GOOGLE_APPLICATION_CREDENTIALS (path to service account JSON) or GOOGLE_OAUTH_*.
CRITICAL: Never write credentials, secrets, or raw user file content to logs. Never include them in tool responses or error messages.
SSRF defense (URL inputs): Allow only https://. Resolve the domain and reject private, reserved, or loopback IP ranges. 10-second connection timeout. 10 MB response size cap.
Upload validation: Verify file type via magic-number sniffing against a strict allowlist (.doc, .docx, .pdf, .odt, .txt). Do not trust filename extension or client-supplied content type.
Size limit: 10 MB hard cap on all incoming documents (uploads, URL fetches, Google Doc exports). Reject oversized inputs immediately.
Content sanitization: Use a vetted library like bleach to strip <script>, <iframe>, event handlers, and dangerous attributes before generating XML or REST payloads.
WXR generation: Build using xml.etree.ElementTree or lxml. Never concatenate XML strings or use f-strings — vulnerable to XML injection.
Error handling: Tools must not raise unhandled exceptions. Return structured errors for predictable failures: {“error”: “unsupported_file_type”}, {“error”: “ssrf_attempt_blocked”}, {“error”: “integration_not_configured”, “missing_env”: [“WORDPRESS_APPLICATION_PASSWORD”]}, etc.
Conditional registration: publish_document_to_wordpress and import_google_doc MUST NOT be registered with the MCP server when their required env vars are absent. The health tool must accurately reflect this.
CRITICAL: Never expose credential values or internal stack traces in tool responses. health returns booleans only.
Examples:
Tool skeleton (apply this pattern to all tools):
from mcp.server.fastmcp import FastMCP
mcp = FastMCP(“wordpress-document-bridge”)
@mcp.tool()
async def convert_document_to_wxr(source: dict, post_type: str, category: str) -> dict:
“””Convert a document (URL or base64 upload) to WXR XML for WordPress import.”””
try:
# 1. Validate `source` shape (URL vs. file_upload)
# 2. Fetch/decode + validate (SSRF guard, magic-number sniff, size cap)
# 3. Parse document text by type (docx/pdf/odt/txt)
# 4. Sanitize content via bleach
# 5. Build WXR using xml.etree.ElementTree
return {“wxr_data”: “<?xml version=\”1.0\”?>…”}
except KnownToolError as e:
return {“error”: e.code, **e.context}
except Exception:
# log internally, do not surface details
return {“error”: “internal_error”}
# Conditional registration based on env-var presence:
if wordpress_credentials_configured():
@mcp.tool()
async def publish_document_to_wordpress(…): …
if google_credentials_configured():
@mcp.tool()
async def import_google_doc(…): …
JSON Schema for the shared source parameter (oneOf for mutually exclusive inputs):
{
“type”: “object”,
“description”: “Document source — either a public URL or a base64 file upload.”,
“properties”: {
“url”: {
“type”: “string”,
“format”: “uri”,
“description”: “Public HTTPS URL to a supported document.”
},
“file_upload”: {
“type”: “object”,
“properties”: {
“filename”: { “type”: “string” },
“content_base64”: { “type”: “string”, “contentEncoding”: “base64” }
},
“required”: [“filename”, “content_base64”]
}
},
“oneOf”: [
{ “required”: [“url”] },
{ “required”: [“file_upload”] }
]
}
Expected health response shape:
{
“status”: “ok”,
“integrations”: {
“wordpress_publish”: true,
“google_docs”: false
},
“supported_formats”: [“docx”, “doc”, “pdf”, “odt”, “txt”],
“available_tools”: [“convert_document_to_wxr”, “publish_document_to_wordpress”, “health”]
}
Scoring the result
RICCE Score: 76 / 100 (judge mode)
| Component | Score | Notes |
| Role | 10/10 | Specifies seniority + relevant security expertise |
| Instruction | 10/10 | Four tools defined unambiguously |
| Context | 6/10 | Trust boundary clear; data sensitivity & expected scale not stated |
| Constraints | 10/10 | Exemplary — credentials, SSRF, file validation, XML injection all covered |
| Examples | 2/10 | Judge note “An exemplary, security-focused prompt whose high quality is not fully reflected in the low baseline scores for context and examples.” |
The Examples score appears to be a deterministic-rubric artifact — the judge explicitly flagged it as inaccurate because the prompt does include a Python skeleton, JSON Schema, and a response example.
Cheap wins to push the score higher
Context (6 → 9): Add one line on data sensitivity (e.g., “Posts may be public marketing copy or contain end-user PII — treat all content as PII-bearing”) and one on scale (e.g., “low-volume internal tool, single-tenant”).
Examples: Add a negative example of a forbidden pattern, and an explicit structured error response sample. E.g.:
# FORBIDDEN: string-built XML — vulnerable to injection
xml = f”<title>{user_title}</title>”
{ “error”: “ssrf_attempt_blocked”, “reason”: “url_resolves_to_private_range” }
Security flag noted: no_chain_of_thought. If the coding agent is reasoning-capable, you don’t need to add anything; if it’s a non-reasoning model, prepend “Think step-by-step before writing code: first plan the module layout, then implement.”
Takeaways
What started as a one-paragraph request — “build an app that turns documents into WordPress imports” — ended as a four-tool MCP server spec with magic-number file validation, SSRF defenses, XML-injection-safe output construction, conditional tool registration based on configured credentials, and a structured error contract. Same idea. Vastly different blast radius if I’d handed the original prompt straight to a coding agent.
That’s RICCE doing its job. But notice what the MCP did beyond rewriting: it refused to commit to a shape until I’d resolved two open questions, one tool or several, and how to handle Google Docs. A coding agent given the vague version would have picked a default and moved on, and I’d have inherited whichever assumption was cheapest to generate. Surfacing ambiguity before code gets written is, frankly, more valuable than any rewrite.
The final score of 76/100 isn’t a perfect ten, and that’s the point. The judge flagged thin context around data sensitivity and expected scale, and the deterministic rubric undercounted the worked examples that were already in the prompt. Both are cheap to fix, and the diagnostics tell you exactly what to add. That’s the 30-second feedback loop the parent article talks about, demonstrated end-to-end on a real project of mine.
Next post, I’ll run the wizard against a real task and show how five plain-English answers assemble into a finished prompt — no manual RICCE writing required.
If you want to see this run live against a prompt of your own — or get a copy of the MCP to use, modify, or fold into your own workflow — reach out and we’ll schedule a demo.
